[프로젝트] 데이터 전처리를 위한 데이터 수집(2)
3. 데이터 학습
3.1) 데이터 학습 모델 선택
LLM(Large Language Model, 대규모 언어 모델)을 선택해야한다.
1) HuggingFaceTransformers 기반의 GPT-2, GPT-J, KoGPT 등을 로컬이나 클라우드 환경에서 파인튜닝하기
2) OpenAI API 등 외부 API 이용해서 파인튜닝
우선은 1번 HuggingFace Transformers 기반의 GPT를 이용해서 로컬에서 파인튜닝을 해보려고 한다.
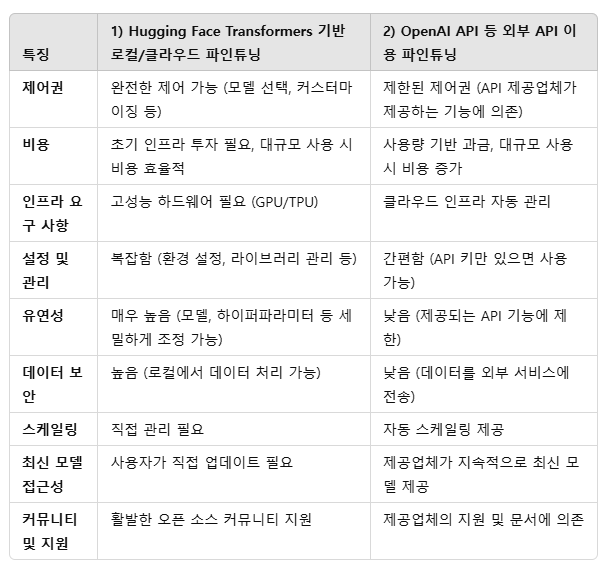
HuggingFace Transformers와 OpenAI API 등 외부 API 이용 시 비교내용이다.
일단은 1번으로 해보고 너무 복잡하면 2로 가야겠다..
3.2) HuggingFaceTransformers
1) 파이썬 설치
파이썬 버전 3.11.0 기준으로 프로젝트를 진행한다.
너무 높은 버전이면 pytorch 설치에서 에러가 발생한다.
2) 라이브러리 설치
pytorch, transformers, pandas, numpy, datasets 등
# PyTorch 설치 (CUDA 11.8 예시)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Hugging Face Transformers 설치
pip install transformers
pip install datasets tqdmPyTorch란?
PyTorch는 신경망을 구축하기 위한 소프트웨어 기반 오픈 소스 딥 러닝 프레임워크로 Torch 머신 러닝 라이브러리와 Python 기반 API를 결합한 것이다(러닝 + Python API)
PyTorch 튜토리얼에서는 아래와 같이 정의하고 있다.
Python 기반의 과학 연산 패키지로 NumPy를 대체하면서 GPU를 이용한 연산이 필요하거나 최대한의 유연성과 속도를 제공하는 딥러닝 연구 플랫폼이 필요한 경우를 대상으로 한다.
PyTorch의 장점은 설치가 간단하고 간결한 코드로 구성되며 파이썬 라이브러리와 높은 호환성을 가진다.
다른 딥러닝 라이브러리로는 텐서플로우, 케라스 등이 있다.
이후에 ex_torch.py 파일 생성 후 아래와 같이 작성하고 python ex_torch.py 로 실행한다.
import torch
print("PyTorch 버전:", torch.__version__)
print("CUDA 사용 가능 여부:", torch.cuda.is_available())
if torch.cuda.is_available():
print("사용 가능한 GPU 개수:", torch.cuda.device_count())
print("첫 번째 GPU 이름:", torch.cuda.get_device_name(0))
자연어 처리(NLP, Natural Language Processing)
NLP는 자연어를 컴퓨터가 이해하고 처리할 수 있도록 하는 기술이다.
텍스트와 음성 데이터를 분석, 이해, 생성하거나 변환하는 데 사용됩니다.
- 전체 문장을 분류하기(Classifying whole sentences): 리뷰(review)의 감정(sentiment)을 식별하고, 이메일이 스팸인지 감지하고, 문장이 문법적으로 올바른지 또는 두 문장이 논리적으로 관련되어 있는지 여부를 판단합니다.
- 단일 문장에서 각 단어를 분류하기(Classifying each word in a sentence): 문장의 문법적 구성요소(명사, 동사, 형용사) 또는 명명된 개체(개체명, e.g., 사람, 위치, 조직) 식별
- 텍스트 컨텐트 생성하기(Generating text content): 자동 생성된 텍스트로 프롬프트 완성(completing a prompt), 마스킹된 단어(masked words)로 텍스트의 공백 채우기
- 텍스트에서 정답 추출하기(Extracting an answer from a text): 질문(question)과 맥락(context)이 주어지면, 맥락에서 제공된 정보를 기반으로 질문에 대한 답변을 추출
- 입력 텍스트에서 새로운 문장을 생성하기(Generating a new sentence from an input text): 텍스트를 다른 언어로 번역(translation), 텍스트 요약(summarization)
정리하자면, 내가 학습시키기에는 데이터부터 전처리 과정이 너무 길고 복잡하기 때문에 미리 학습된 것을 파인튜닝하려고 한다.
LLM 모델 구축 방법 1) 제로 베이스에서 직접 LLM 모델 개발 2) 파인튜닝 3) 사전 훈련모델 + retrieve(RAG) 중 2번 적용을 선택한 것이다.
아래는 RAG와 파인튜닝 중 내가 파인튜닝을 고른 이유다.
왜 파인튜닝인가?
LLM의 행동을 특정한 뉘앙스나 톤, 용어 등에 맞추려고 하면 파인 튜닝이 더 유리하다.
나는 타로 앱으로 사용할 거라 "~바라" 말투가 필요해서 파인튜닝을 골랐다.
할루시네이션에 대한 고민은 사실 좀 덜한게 내가 정한 질문 형태로만 질문할 것이라 이미 타로 도메인 데이터 학습을 시키면 input을 제한적으로 넣을거라 예상 값 내에서 나올 수 있을 것이라 생각한다.
파인튜닝 모델의 품질은 내가 넣는 도메인 데이터 품질과 양이 중요하다. 다만 RAG에 의존하기도 적절하지 않다고 판단해서 모델 잘 주워서 넣어보자ㅎㅎ;
HuggingFace에서 다양한 NLP 모델과 라이브러리를 제공하는데 HuggingFace Transformers는 HuggingFace가 만든 딥 러닝을 위한 오픈소스 프레임워크이다.
미리 학습된 최신 모델을 다운로드하고 성능을 최대화하기 위해 추가로 조정하는 API 및 도구를 제공한다고 한다.
HuggingFace와 Transformers는 아래의 접은 글을 참고하자.
1. Hugging Face란?
Hugging Face는 기계 학습, 특히 자연어 처리(NLP) 분야에서 혁신적인 도구와 서비스를 제공하는 회사이자 커뮤니티입니다. Hugging Face는 연구자, 개발자, 데이터 과학자들이 쉽게 최첨단 NLP 모델을 사용하고 공유할 수 있도록 다양한 리소스를 제공합니다.
주요 기능 및 서비스:
- 모델 허브(Model Hub):
- 다양한 사전 학습(pre-trained)된 모델들을 공유하고 검색할 수 있는 플랫폼입니다.
- 사용자들은 자신이 훈련시킨 모델을 업로드하고, 다른 사람들이 이를 다운로드하여 사용할 수 있습니다.
- Transformers 라이브러리:
- 후에 자세히 설명할 Transformers 라이브러리는 Hugging Face에서 개발한 오픈 소스 라이브러리로, 다양한 트랜스포머 기반 모델을 손쉽게 사용할 수 있게 해줍니다.
- Datasets 라이브러리:
- 다양한 데이터셋을 쉽게 로드하고 전처리할 수 있는 도구를 제공합니다.
- 커뮤니티 및 포럼:
- 사용자들이 질문을 하고, 지식을 공유하며, 협업할 수 있는 커뮤니티 공간을 제공합니다.
- Inferences API:
- 클라우드에서 모델을 호스팅하고, API를 통해 쉽게 접근할 수 있는 서비스입니다.
Hugging Face의 장점:
- 사용 용이성: 복잡한 모델을 간단한 코드로 불러와 사용할 수 있어, 비전문가도 쉽게 접근할 수 있습니다.
- 광범위한 모델 지원: BERT, GPT, T5, RoBERTa 등 다양한 트랜스포머 모델을 지원합니다.
- 커뮤니티 중심: 활발한 커뮤니티 덕분에 지속적으로 새로운 모델과 업데이트가 제공됩니다.
2. Transformers란?
Transformers는 Hugging Face에서 개발한 오픈 소스 라이브러리로, 트랜스포머(Transformer) 아키텍처를 기반으로 한 다양한 모델들을 쉽게 사용할 수 있게 해줍니다. 트랜스포머 아키텍처는 자연어 처리에서 혁신적인 성과를 이룬 모델 구조로, 특히 시퀀스-투-시퀀스 작업에서 뛰어난 성능을 보입니다.
주요 특징:
- 다양한 사전 학습 모델 제공:
- BERT, GPT-2, GPT-3, T5, RoBERTa 등 다양한 트랜스포머 기반 모델을 제공합니다.
- PyTorch 및 TensorFlow 지원:
- 두 주요 딥러닝 프레임워크인 PyTorch와 TensorFlow를 모두 지원하여, 사용자가 선호하는 프레임워크를 선택할 수 있습니다.
- 간편한 모델 로딩 및 사용:
- 사전 학습된 모델을 몇 줄의 코드로 불러와 사용할 수 있습니다.
- 파인튜닝(Fine-tuning) 지원:
- 특정 작업에 맞게 사전 학습된 모델을 재학습시킬 수 있는 기능을 제공합니다.
- 강력한 커뮤니티 지원:
- 다양한 튜토리얼, 문서, 예제 코드가 제공되어 학습과 개발에 도움을 줍니다.
Transformers의 장점:
- 확장성: 대규모 모델도 효율적으로 처리할 수 있도록 설계되었습니다.
- 유연성: 다양한 NLP 작업(텍스트 분류, 번역, 생성, 질의응답 등)에 맞게 쉽게 적용할 수 있습니다.
- 최신 기술 반영: 트랜스포머 아키텍처의 최신 연구 성과를 빠르게 반영하여 업데이트됩니다.
Hugging Face와 Transformers의 관계
- Hugging Face는 Transformers 라이브러리를 개발하고 유지 관리하는 주체입니다.
- Transformers 라이브러리는 Hugging Face의 핵심 제품 중 하나로, Hugging Face의 모델 허브와 긴밀하게 통합되어 있습니다.
- Hugging Face의 모델 허브에 업로드된 사전 학습 모델을 Transformers 라이브러리를 통해 쉽게 불러와 사용할 수 있습니다.
요약
- Hugging Face는 자연어 처리와 기계 학습을 위한 다양한 도구와 서비스를 제공하는 플랫폼입니다.
- Transformers는 Hugging Face에서 개발한 오픈 소스 라이브러리로, 트랜스포머 아키텍처 기반의 다양한 모델을 손쉽게 사용할 수 있게 해줍니다.
- Hugging Face와 Transformers를 활용하면, 복잡한 모델을 쉽게 적용하고, 커뮤니티와 협업하며, 최신 NLP 기술을 빠르게 도입할 수 있습니다.
정리하자면 HuggingFace는 NLP와 ML을 위한 다양한 도구와 서비스를 제공하는 플랫폼이고 Transformers는 HuggingFace에서 개발한 오픈소스 라이브러리로 트랜스포머 아키텍처 기반의 다양한 모델을 쉽게 사용하게 도와준다.
4. GPT 아키텍처 이해
GPT 아키텍처는 자연어 처리 분야에 혁신을 가져온 Transformer 모델을 기반으로 구축되었다.
Transformer 모델은 Vaswani 등이 발표한 "Attention is All You Need" 논문에서 소개된 것으로 GPT를 비롯한 많은 현대적인 NLP 모델의 기반이다.
Transformer 모델은 인코더와 디코더라는 두 가지 주요 구성 요소로 이루어져 있지만 GPT 모델에서는 디코더 부분만 사용한다.
Transformer 모델의 중요한 특징은 재귀적으로 시퀀스를 처리하는 순환 신경망(RNN)과 달리 입력 시퀀스를 병렬로 처리할 수 있는 능력이다. 이러한 특성은 훈련 시간을 크게 단축시켰다.
5. 사전 훈련된 GPT 모델 선택
파인튜닝할 모델을 선택해야한다.
GPT-2, GPT-3, T5, BERT 기반 모델들이 있는데 구글의 BERT냐 OpenAI의 GPT냐..

우선은 GPT-2를 사용하려고 한다.
비용적인 문제와 우선적으로 구현이 목표이기 때문에 GPT-2로 해보려고 한다.
6. 데이터 정리
사실 관련 데이터 찾는 부분에서 조금 애를 먹었다.
마땅히 정리가 잘된 json 데이터가 없기도 해서 어떤걸 학습시키는 게 좋을지 고민이었다.
직접 데이터를 정리하게 되었고 카드 78개를 기준으로 의미와 해석을 정리했다.
[
{
"카드번호": 0,
"카드": "The Fool",
"정방향": {
"운세": "",
"사랑": "",
"커리어": "",
"금전": "",
"건강": ""
},
"역방향": {
"운세": "",
"사랑": "",
"커리어": "",
"금전": "",
"건강": ""
},
"YES_OR_NO": "YES"
},
...
]이런 형태의 json으로 파일 하나를 만들었다.